
Creating a Project Sonar FDNS API with AWS (Part 1)
imported from https://2xxe.com/posts/2/
Intro
Project Sonar is an initiative by Rapid7 where they perform internet-wide scanning then make the results available publicly for free. This data covers areas like HTTP resonses, DNS records, and SSL certificates, and is accessible from their opendata site in the form of GZipped downloads released semi-regularly. This type of data can be extrememly useful during an offensive engagement as it can help to develop a more thorough footprint of the target, which is the sum of the target’s external presense and includes things like registered domains and IP ranges. Recently, the Forward DNS (FDNS) data set was made available via a public S3 bucket on Amazon’s Open Data Registry. In this blog post, I will walk through creating an HTTP API to query this dataset.


API Components
AWS S3: Object storage
AWS Lambda: Functions as a service
AWS API Gateway: Managed API management; provides HTTP API interface for Lambdas
AWS Glue: Data extraction, transformations, and loading (ETL)
AWS Athena: Service to allow querying of data in S3 using SQL
AWS Athena
AWS Athena is a managed Presto service that allows users to query data in S3 using SQL. In this project, it will be used to query the FDNS data from the public S3 bucket. Each query in Athena generates an ID that can be used to retrieve query results, which are in the form of a CSV stored in an S3 bucket (if you don’t specify one, it will generate one with a name like aws-athena-query-results-*). There are three important things to keep in mind when using Athena:
Cost is determined by the volume of data being searched
If you own the S3 bucket being searched, you will also incur S3 data fees. In this case, the bucket is not under our control, so we only pay for searching, not storage (except for the results CSV, which is saved to your account)
You only get charged for the data you search, meaning you will incur half the charge if you only search half of the columns
You can use formats like Parquet for storing data in a columnar format
Stored data can be GZipped
This can be used to reduce search fees but will increase the time it takes to query the data
Refer to this page for more information
API Overview
The API itself is fairly straighforward. The user will perform an HTTP request to API Gateway with a domain to search. API Gateway will proxy that request to Lambda. Lambda will initiate an Athena query against the public S3 bucket containing the FDNS data then return a transaction ID to the user. After waiting for the query to complete (approximately a minute), the user will make another HTTP request, this time with the transaction ID. API Gateway will pass that to a differnt Lambda, which will retrieve the query results. If there are any results, a presigned S3 URL will be generated for the CSV of results.
Creating the Tables
The first step for creating this API will be to create an Athena database and table for the FDNS data. There are two approaches we can take for this. The first is to analyze the data’s schema then formaluate a create table query from it. The second is to leverage AWS Glue. A useful feature of Glue is that it can crawl data sources. Once crawled, Glue can create an Athena table based on the observed schema or update an existing table. For the purposes of this walkthrough, we will use the latter method. From the AWS console, go to Glue, then crawlers, then add crawler.


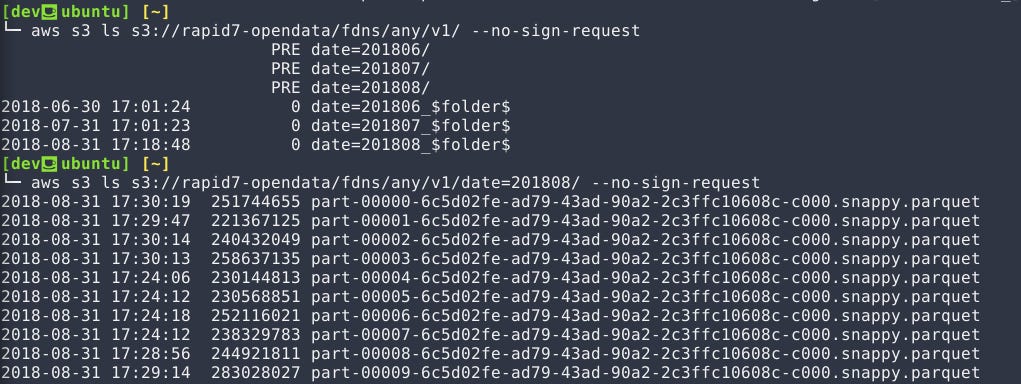
Before completing this configuration, we can briefly inspect the data we are about to crawl using the awscli:
aws s3 ls s3://rapid7-opendata/fdns/any/v1/date=201808 --no-sign-requestNotice that the data is split into multiple fragments. These fragments are Parquet files, which can help to reduce querying costs.

Using that same bucket, complete the next crawler configuration step.


Following that, create a service role and set the schedule to on-demand. The fifth step is where the Athena integration occurs. Here we set the database that the table will be created as well as any addtional configuration the user desires.


Once the crawler is created, you can schedule it to run against the bucket. This process should complete in approximately 30 seconds. After completion, you can view the results of the crawl, including the resulting Athena table, in the Glue UI.

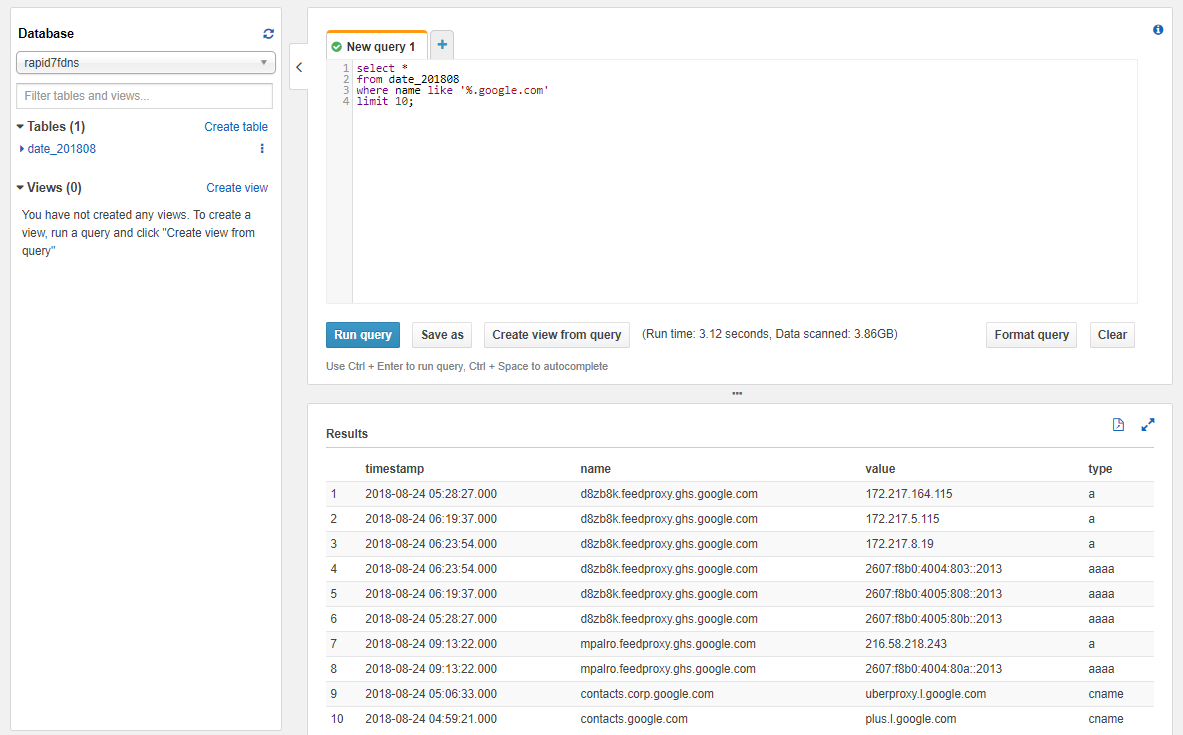
To verify the results, we can run a query from the Athena console. As an example, I used the following query:
select *
from date_201808
where name like '%.google.com'
limit 10;This should return the first ten results where the record value is a subdomain of google.com (output below).

API-ify the Data
With the query capabilities in place, we can now create the HTTP interface. To start, we’ll need two Lambda functions. One will be used to query the data via Athena and the second will be used to retrieve the results. Example code is shown below. Please note that this example code is meant to provide the bare minimum needed to complete the task. Feel free to customize it to your liking.
Run query Lambda:
import json, boto3, os
def lambda_handler(event, context):
if event['queryStringParameters']['domain'] is None:
return {"isBase64Encoded":False,"statusCode":400,"body":json.dumps({"error":"missing input domain"})}
domain = '%%.%s' % str(event['queryStringParameters']['domain'])
athenabucket = os.getenv('ATHENA_S3_BUCKET',None)
athenatable = os.getenv('ATHENA_TABLE',None)
athenadb = os.getenv('ATHENA_DATABASE',None)
if athenatable is None or athenabucket is None or athenadb is None:
return {"isBase64Encoded":False,"statusCode":400,"body":json.dumps({"error":"misconfigured environment"})}
athenabucket = 's3://%s' % athenabucket
athena = boto3.client('athena')
query = "SELECT * FROM %s WHERE name LIKE '%s';" % (athenatable,domain)
qexec = athena.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database':athenadb
},
ResultConfiguration={
'OutputLocation':athenabucket
}
)
execid = qexec['QueryExecutionId']
if execid is not None:
return {"isBase64Encoded":False,"statusCode":200,"body":json.dumps({"execution_id":execid})}
else:
return {"isBase64Encoded":False,"statusCode":500,"body":json.dumps({"error":"error performing query"})}This function uses three environment variables:
ATHENA_DATABASE: the name of the Athena database
ATHENA_S3_BUCKET: the name of the output bucket
ATHENA_TABLE: the name of the Athena table
Retrieve results Lambda:
import json, boto3
def lambda_handler(event, context):
if event['queryStringParameters']['execution_id'] is None:
return {"isBase64Encoded":False,"statusCode":400,"body":json.dumps({"error":"missing input domain"})}
execid = event['queryStringParameters']['execution_id']
athena = boto3.client('athena')
s3 = boto3.client('s3')
queryres = athena.get_query_execution(
QueryExecutionId = execid
)
try:
outputloc = queryres['QueryExecution']['ResultConfiguration']['OutputLocation']
full = outputloc[5:] #trim s3:// prefix
bucketloc = full.split('/')[0] #get bucket from full path
keyloc = full.replace(bucketloc,'')[1:] #get key and remove starting /
url = s3.generate_presigned_url(
'get_object',
Params={
'Bucket':bucketloc,
'Key':keyloc
}
)
return {"isBase64Encoded":False,"statusCode":200,"body":json.dumps({"results":url})}
except:
return {"isBase64Encoded":False,"statusCode":200,"body":json.dumps({"results":"no results"})}For the execution role, the Lambdas will need, at a minimum, access to run Athena queries, retrieve results, and read/write from S3 (the athena results bucket mentioned above). For testing, you can make use of the AWSQuicksightAthenaAccess managed policy.
Next, we’ll need to create the API Gateway for the Lambdas. Normally, Lambdas must be invoked either through the InvokeFunction API or by being triggered from another event. API Gateway however provides the ability to proxy HTTP requests to Lambda functions via the Lambda proxy integration resource type. In the AWS console, navigate to API Gateway and create an API then a GET resource within that API.


Make sure to select the Lambda proxy integration option. For the function, select the Lambda that performs the search. After saving, select the method request block in the resource overview. Here we can configure the requirements for inbound HTTP API requests. Since this is a GET request, we only need to validate the parameters and headers, and not the body. Add a query string parameter named domain and check the required option. This will be the parameter users specify to search.


Repeat this process for the retrieve Lambda function. The options are exactly the same, save for the name of the query string parameter, which should be set to execution_id.
Once complete, deploy the API. In the stage editor, you should see the Invoke URL. Make note of the subdomain as it will be used shortly. The stage editor provides a number of useful functions for configuring your API, such as logging and rate limiting. Its recommended that you spend a few minutes looking through it and adjusting settings to your needs.
Lastly, we need to configure some form of access restrictions. Personally, I prefer to set an IP based resource policy so that my fellow team members can perform queries without needing to worry about authentication. However, if you require stricter controls, consider implementing a custom authorizer on your API Gateway. An example IP-based resource policy is shown below.


In the resource section, change the first blurred value to your AWS account number and the second blurred value to the subdomain of your Invoke URL. Replace the third blurred item with your IP. Refer to this post for a more detiled walkthrough.
Querying the API
The API is now complete. To test, we can curl the Invoke URL. Make sure to include the appropriate paths and query string paramters in the request.
Searching for a domain:


The API returns an ID value. After waiting about a minute, we can retrieve the results:




Closing Thoughts
Hopefully, you will be able to use this API to improve your footprinting activities. If you liked this post, stay tuned for the follow-up post where I will cover a similar process for non-S3 Project Sonar data as well as automating the retrieval and crawling steps.